以下是一个简单的爬取豆瓣电影top250
我们可以通过网页源代码看到

我们可以使用Python的request库先获取整个网页内容,lxml打辅助,分析网页内容,然后提取我们所需要的内容。
def curl_page(i):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
user_agent = { 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' ,
'Referer':'http://www.douban.com' }
# 获取网页内容
content = requests.get(url).content.decode('utf-8')
html = etree.HTML(content)
item = html.xpath('//ol/li/div[@class="item"]')
for i in item:
url = i.xpath('./div[@class="pic"]/a/@href')[0]
pic_url = i.xpath('./div[@class="pic"]/a/img/@src')[0]
title = i.xpath('./div[@class="info"]//a/span[@class="title"]/text()')
name = title[0].encode('UTF-8','ignore').decode('UTF-8')
alias = title[1].lstrip(' / ') if len(title)==2 else ""
score = i.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()')[0]
assess = i.xpath('.//div[@class="star"]/span/text()')[-1]
quote_tag = i.xpath('.//p[@class="quote"]/span[@class="inq"]/text()')
quote = quote_tag[0].encode('UTF-8','ignore').decode('UTF-8') if len(quote_tag) else ""
在这里需要注意编码的问题,由于是在windows终端下跑的,故会报出如下错误,
UnicodeEncodeError: gbk' codec can't encode character '\xa0' in position 10: illegal multibyte sequence
这是由于里面含有特殊字符 ,转换为GBK编码的字符串,但是\xa0这个unicode字符没有对应的GBK编码的字符串,所以会出现错误。
ok ,接下来我们把这些信息存储到Mysql中,这里用的是mysql-python
conn = MySQLdb.connect(host='localhost',user='root',passwd="root",db="test",charset="utf8")
db = conn.cursor()
sql = 'insert into movie(url,pic_url,name,alias,score,assess,quote) values("%s","%s","%s","%s","%s","%s","%s")'%(url,pic_url,name,alias,score,assess,quote)
db.execute(sql)
conn.commit()
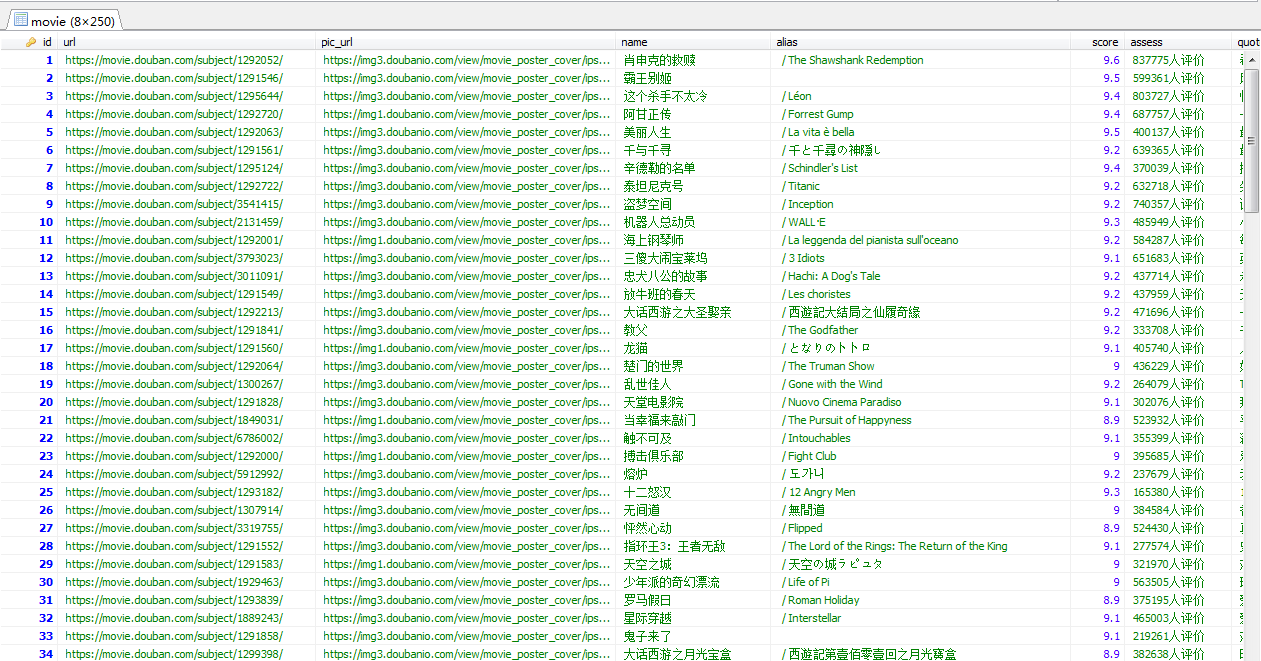
数据库的数据如下图所示